 LION
: Empowering
Multimodal Large Language Model with Dual-Level Visual
Knowledge
LION
: Empowering
Multimodal Large Language Model with Dual-Level Visual
Knowledge
- School of Computer Science and Technology, Harbin Institute of Technology, Shenzhen
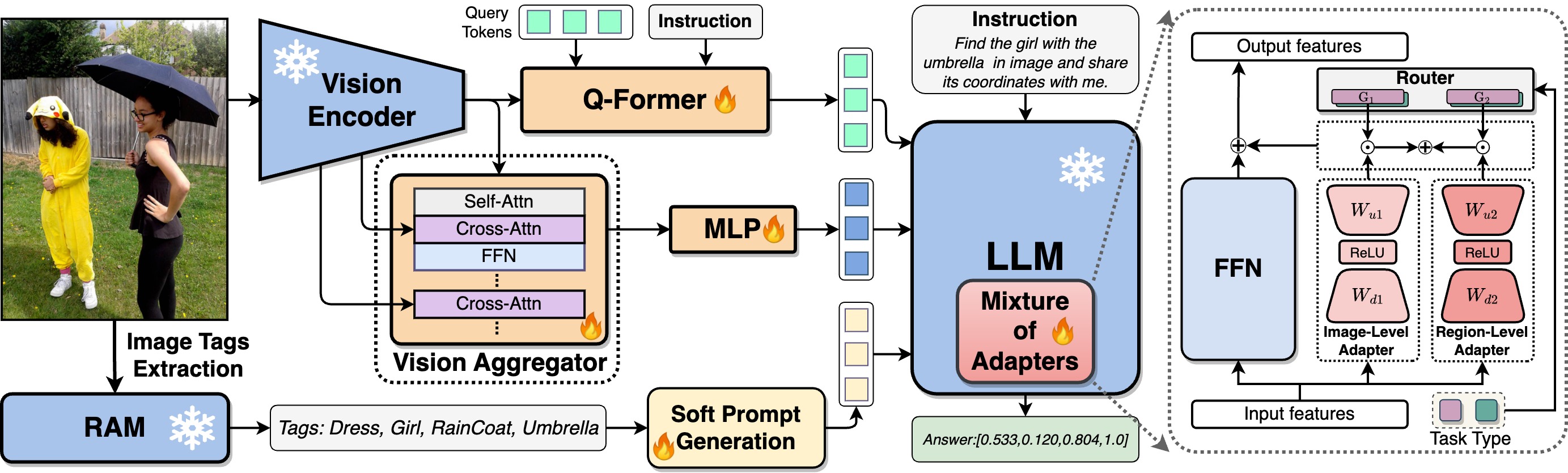
As shown in the figure below, LION model 1) extracts holistic visual features from Q-Former, and combines them with fine-grained spatial-aware visual features from the vision aggregator. 2) The frozen recognize anything model (RAM) produces image tags, which are cooperated with soft prompt to provide complementary high-level semantic visual evidences. 3) The Mixture-of-Adapters with a router in the frozen LLM dynamically fuses visual knowledge learned from different visual branches and LLM adapters based on the task types (image-level and region-level).
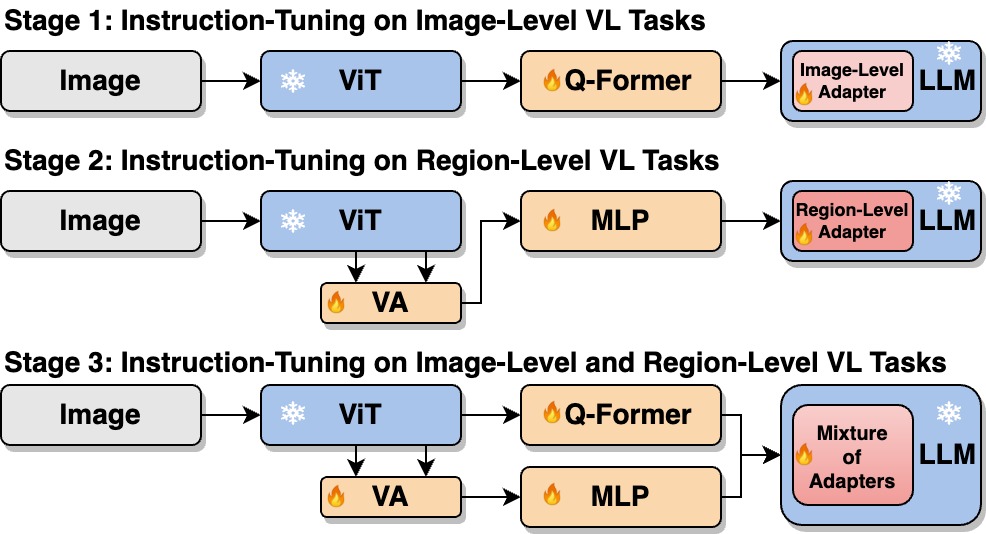
Stage-wise Training Strategy
In order to address the tasks conflicts between region-level and image-level, we adopt a stage-wise instruction-tuning strategy.
- Stage 1: We instruction-tune Qformer and adapter on image-level vision-language (VL) tasks.
- Stage 2: We instruction-tune vision aggregator (VA), MLP and adapter on region-level VL tasks.
- Stage 3: The Mixture-of-Adapters is devised to form a unified model for instruction-tuning on all VL tasks.
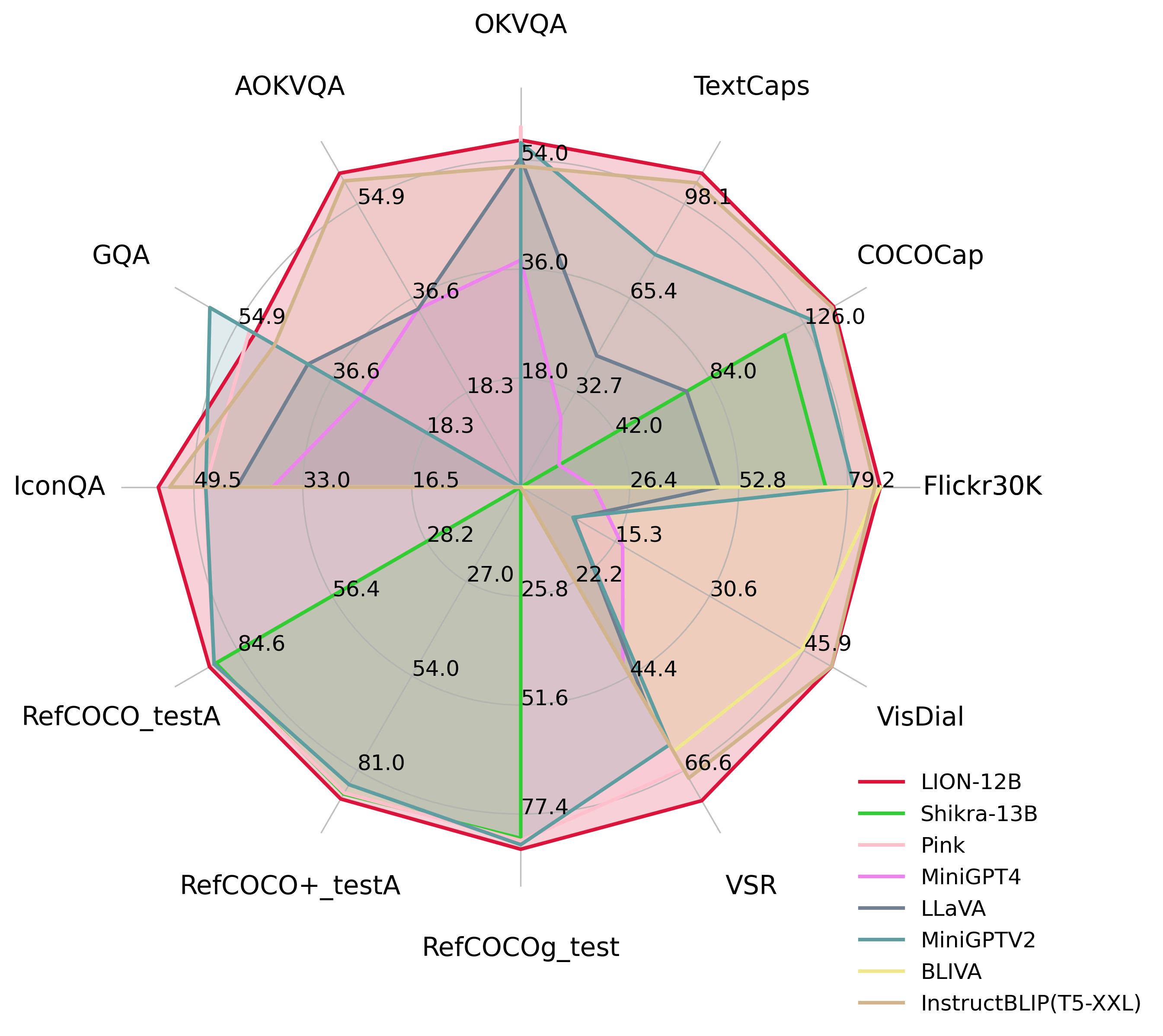
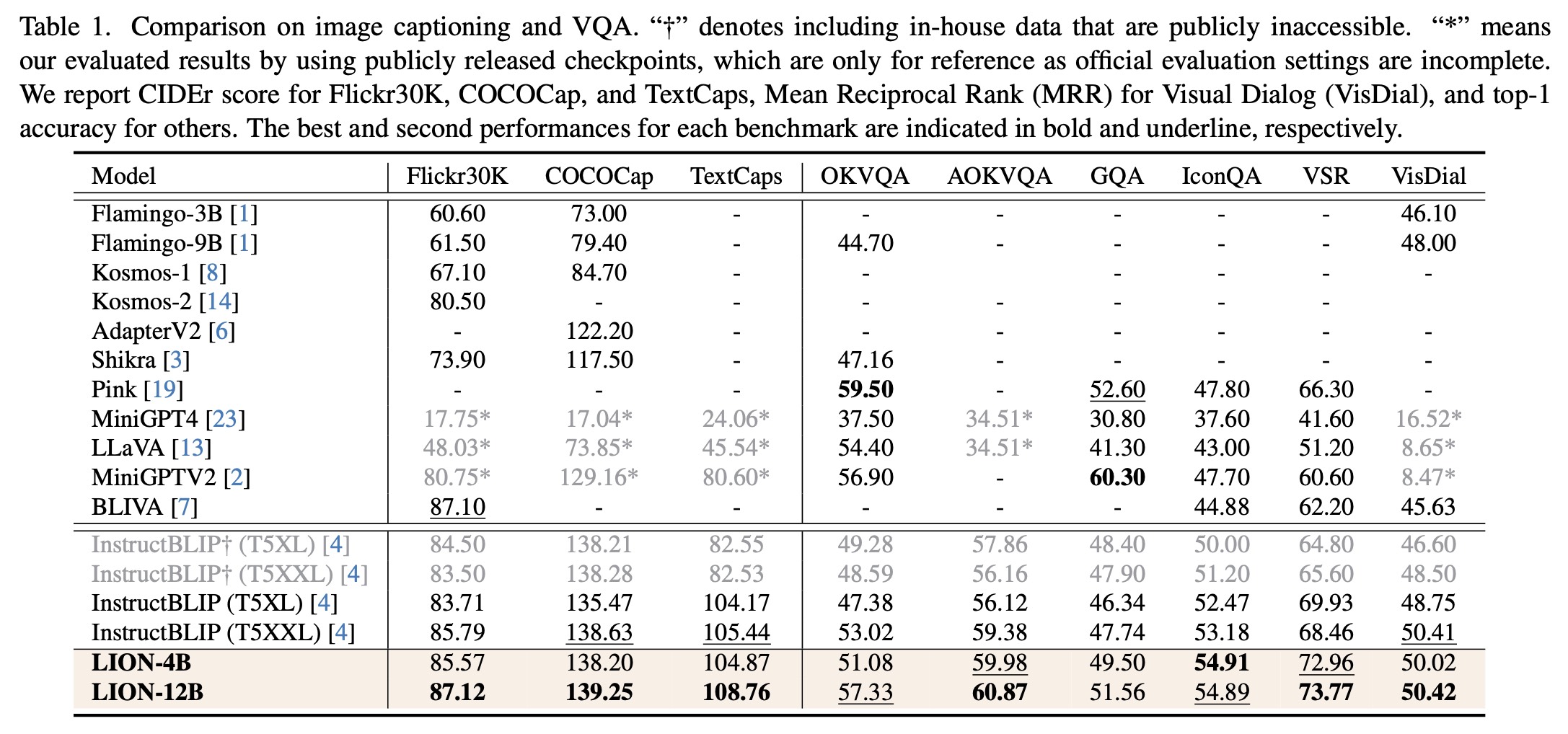
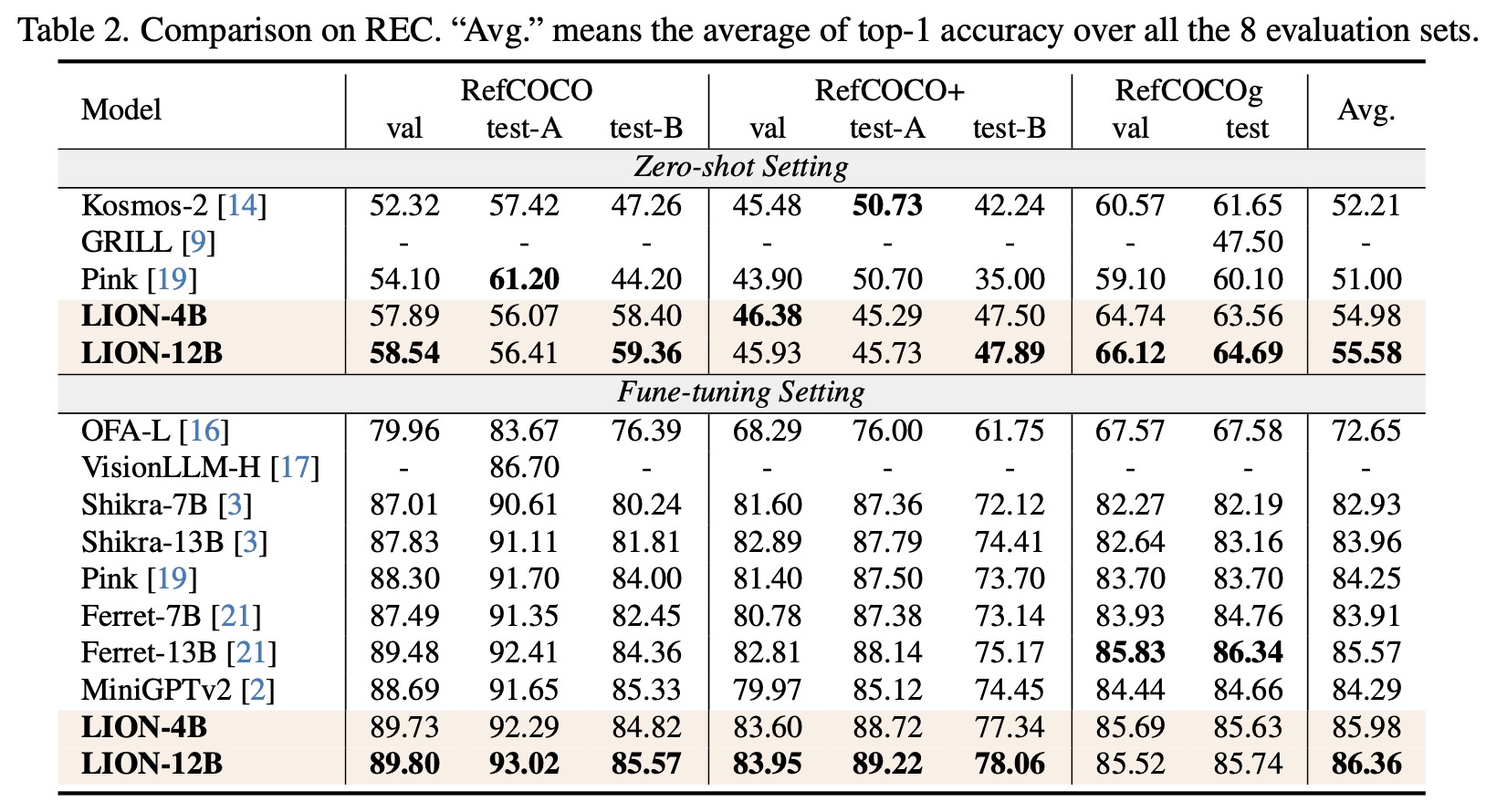
For image-level tasks, we focus on image captioning and Visual Question Answering (VQA). For region-level tasks, we evaluate LION on three REC datasets including RefCOCO, RefCOCO+ and RefCOCOg. The results, detailed in Table 1~2, highlight LION's superior performance compared to baseline models.
Benchmark Results
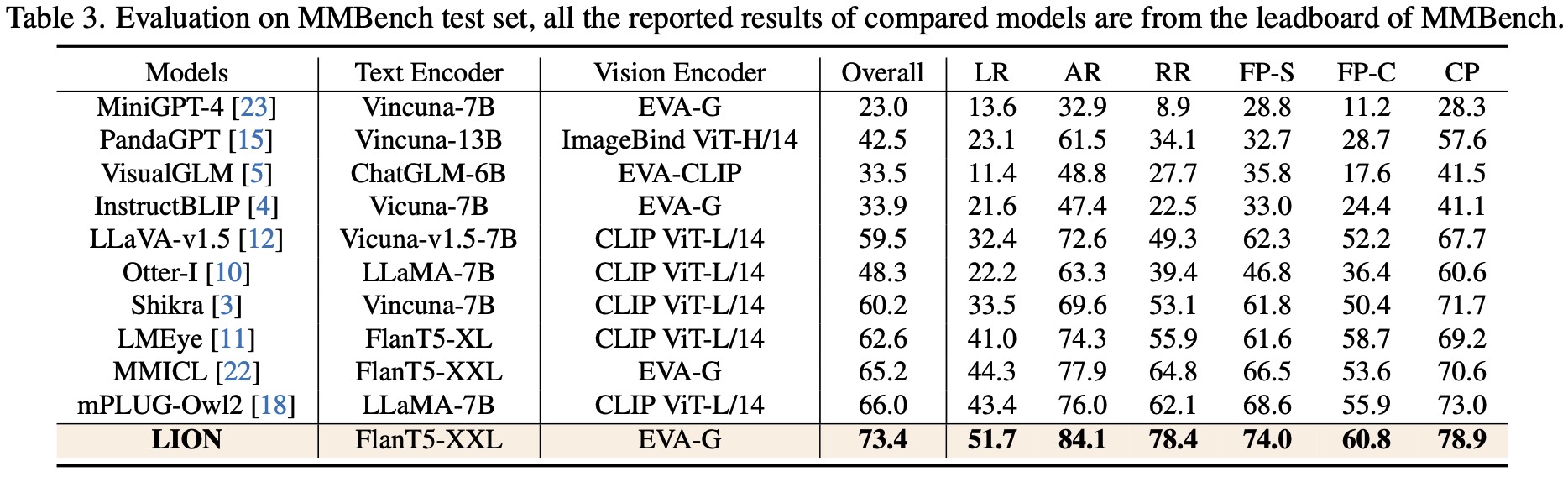
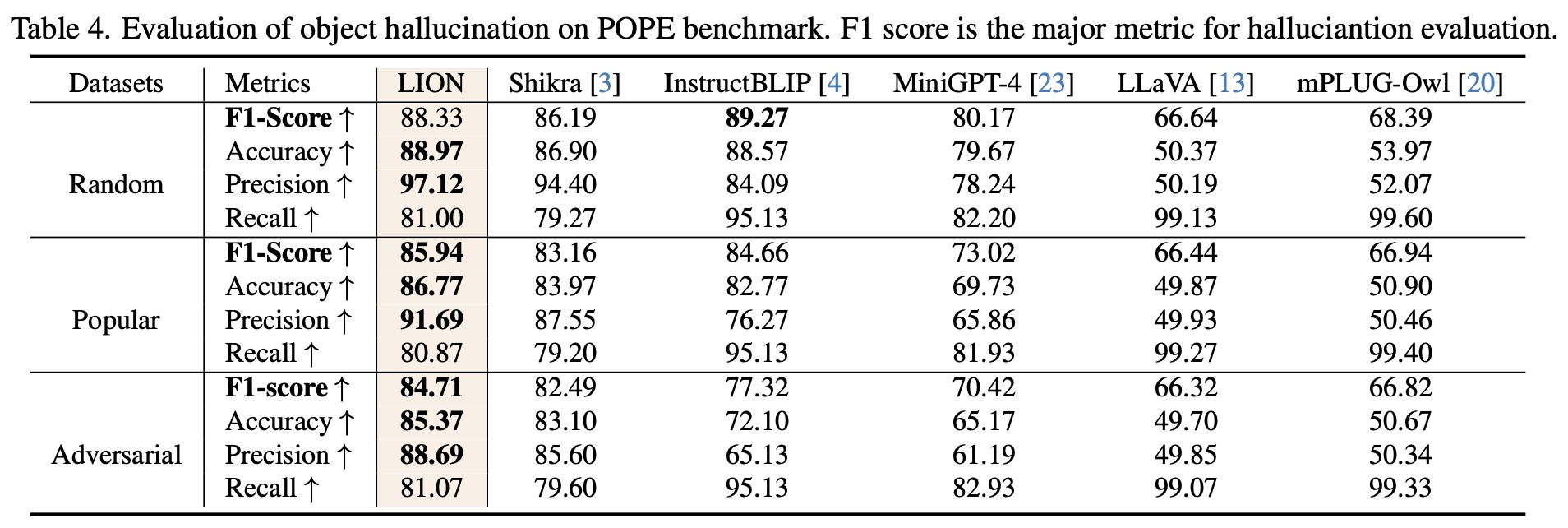
We further evaluate LION on a object hallucination benchmark(POPE) and the most popular MLLM benchmark (MMBench). The results in Table 3~4 show that LION has strong performances across various skills and also demonstrates a strong resistance to hallucinations, particularly in popular and adversarial settings in POPE.
Qualitative Comparison



More Examples

@inproceedings{chen2024lion,
title={LION: Empowering Multimodal Large Language Model with Dual-Level Visual Knowledge},
author={Chen, Gongwei and Shen, Leyang and Shao, Rui and Deng, Xiang and Nie, Liqiang},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}We referred to the project page of AvatarCLIP when creating this project page.