DGM4: Detecting and Grounding Multi-Modal Media Manipulation
- 1School of Computer Science and Technology, Harbin Institute of Technology (Shenzhen)
- 2S-Lab, Nanyang Technological University
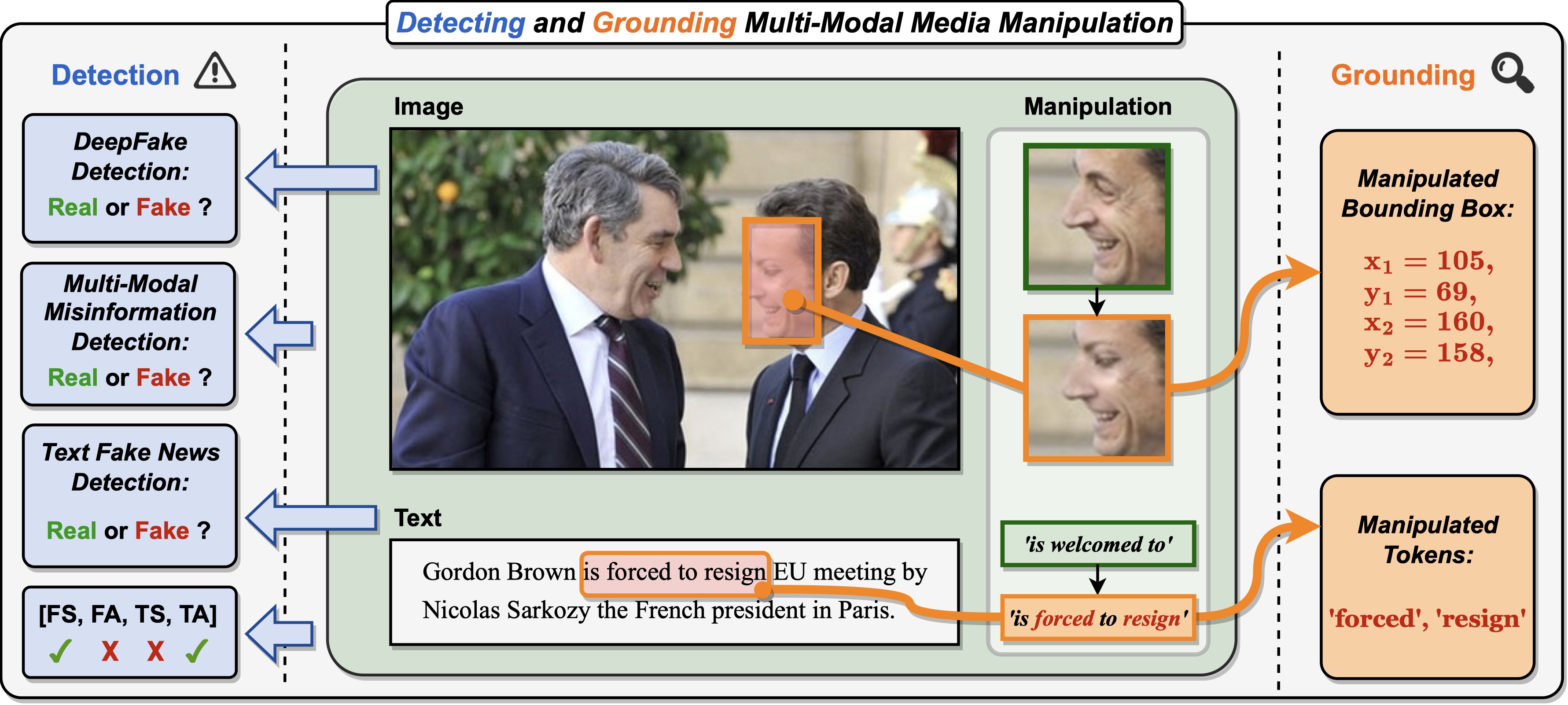

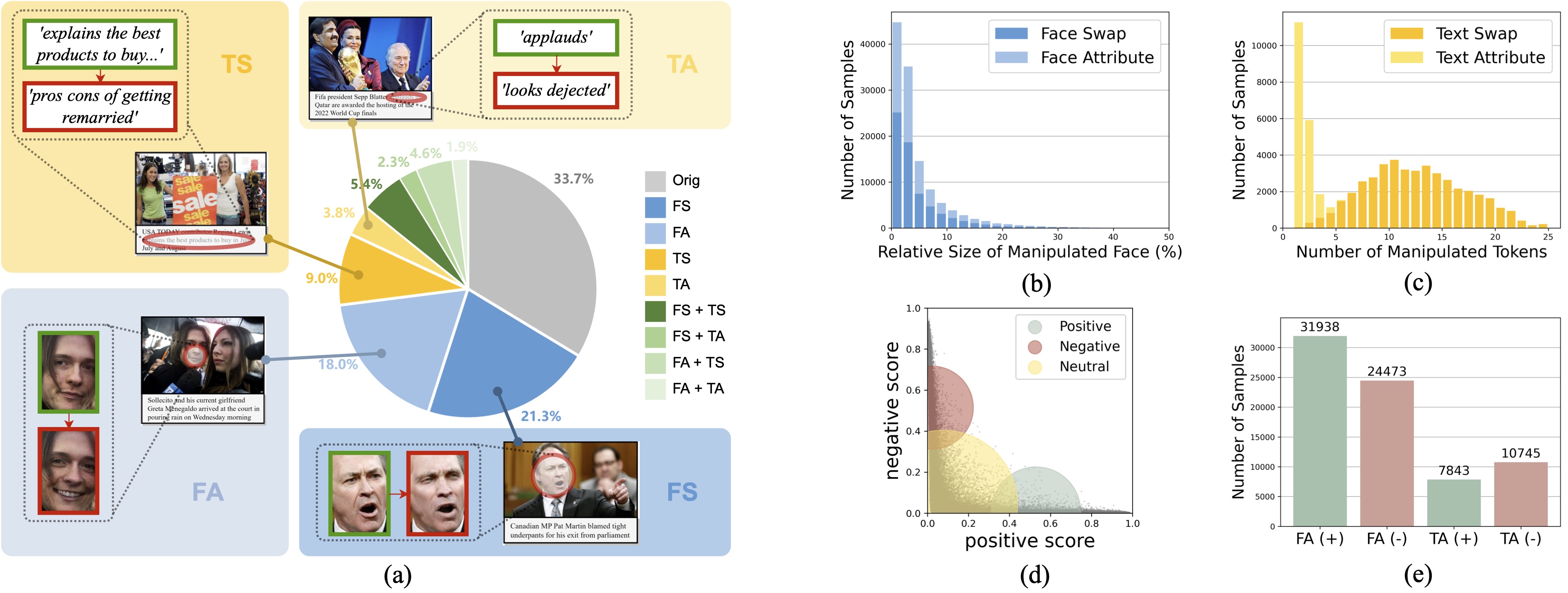
We present DGM4, a large-scale dataset for studying machine-generated multi-modal media manipulation.
The dataset specifically focus on
- 66,722 Face Swap Manipulations (FS)
- 56,411 Face Attribute Manipulations (FA)
- 43,546 Text Swap Manipulations (TS)
- 18,588 Text Attribute Manipulations (TA)
Where 1/3 of the manipulated images and 1/2 of the manipulated text are combined together to form 32,693 mixed-manipulation pairs.
Some sample images and their annotations are shown below. For more information about the data structure, annotation details and other properties about the dataset, you can refer to our github page.



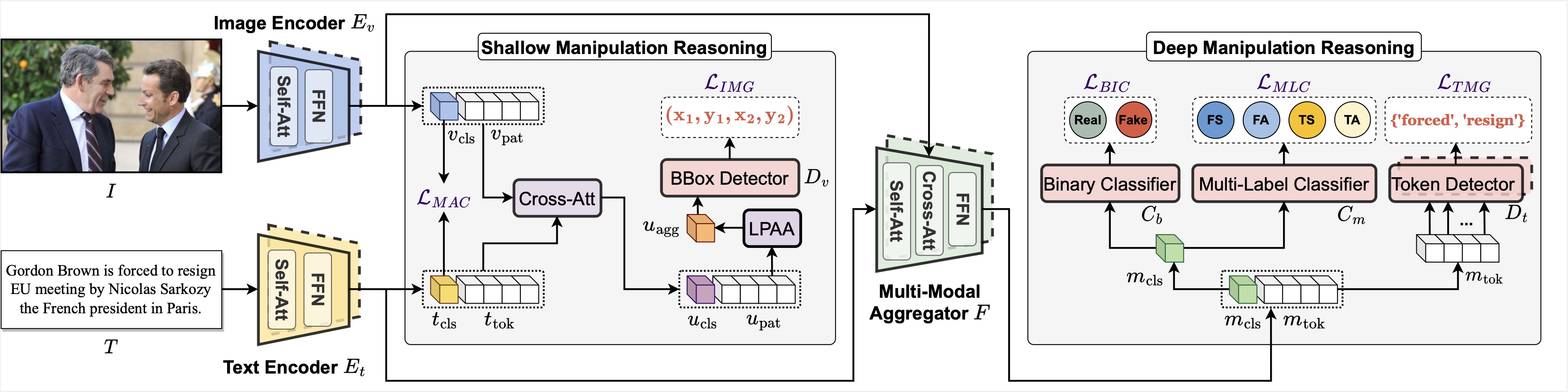
Figure below shows the architecture of proposed HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER). It 1) aligns image and text embeddings through manipulation-aware contrastive learning between Image Encoder Ev, Text Encoder Et in shallow manipulation reasoning and 2) further aggregates multi-modal embeddings via modality-aware cross-attention of Multi-Modal Aggregator F in deep manipulation reasoning. Based on the interacted multi-modal embeddings in different levels, various manipulation detection and grounding heads (Multi-Label Classifier Cm, Binary Classifier Cb, BBox Detector Dv, and Token Detector Dt) are integrated to perform their tasks hierarchically.
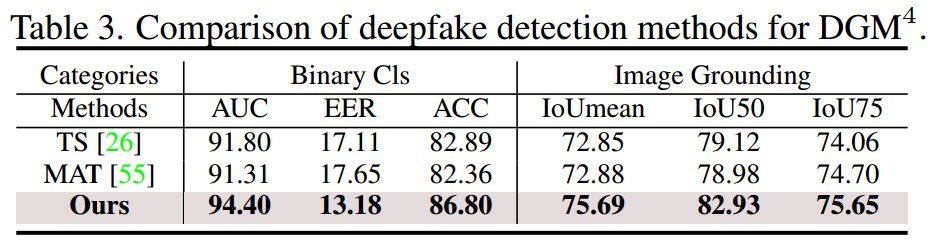
Benchmark results
Based on the DGM4 dataset, we provide the first benchmark for evaluating model performance on our proposed task. To validate the effectiveness of our HAMMER model, we adapt SOTA multi-modal learning methods to our DGM4 setting for full-modal comparision, and further adapt deepfake detection and sequence tagging methods for single-modal comparison. As shown in the tables, HAMMER outperforms all multi-modal and single-modal methods in all sub-tasks, under all evaluation metrics.


Visualization results
Visualization of detection and grounding results. Ground truth annotations are in red, and prediction results are in blue. The visualization results show that our method can accurately ground the manipulated bboxes & text tokens, and successfully detect the manipulation types.

Visualization of attention map. We plot Grad-CAM visualizations with respect to specifc text tokens (in green) for all the four manipulated types. For FS and FA, we visualize the attention map regarding some key words related to image manipulation. For TS and TA, we visualize the attention map regarding the manipulated text tokens. The attention maps show our model can use text to facilitate locating manipulated image regions, and capture subtle semantic inconsistencies between the two modalities to tackle DGM4.

@inproceedings{shao2023dgm4,
title={Detecting and Grounding Multi-Modal Media Manipulation},
author={Shao, Rui and Wu, Tianxing and Liu, Ziwei},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023}
}
We referred to the project page of AvatarCLIP when creating this project page.