SeqDeepFake: Detecting and Recovering Sequential DeepFake Manipulation
- S-Lab, Nanyang Technological University


Seq-DeepFake is the first large-scale dataset for Sequential DeepFake Manipulation Detection. It consists of 85k sequentially manipulated face images, each with ground-truth sequence annotation. The dataset includes high diversity manipulation sequences with lengths from 0 to 5, and is generated based on two different facial manipulation methods:
- Sequential facial components manipulation
- 35,166 number of face images
- 28 types of manipulation sequences
- Sequential facial attributes manipulation
- 49,920 number of face images
- 26 types of manipulation sequences
Some sample images and their annotations are shown below (Mouse Over: the original image). For more information about the data structure, annotation details and other properties about the dataset, you can refer to our github page.

Bangs-Smiling

eyebrow-nose

Eyeglasses

eye-lip-nose-eyebrow-hair

eye

Beard-Bangs-Eyeglasses-Young

lip-nose-eye

Young
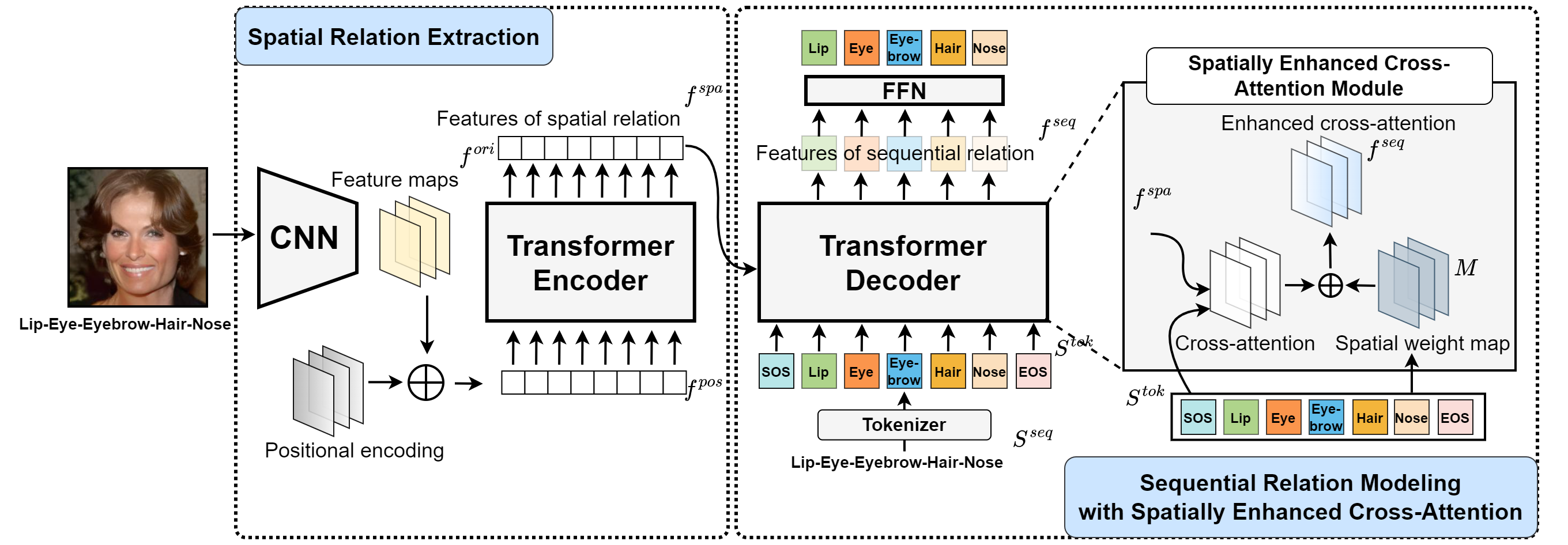
Figure below shows the architecture of proposed Seq-DeepFake Transformer (SeqFakeFormer). We first feed the face image into a CNN to learn features of spatial manipulation regions, and extract their spatial relation via self-attention modules in the encoder. Then sequential relation based on features of spatial relation is modeled through cross-attention modules deployed in the decoder with an auto-regressive mechanism, detecting the sequential facial manipulation. A spatial enhanced cross-attention module is integrated into the decoder, contributing to a more effective cross-attention.
Benchmark results
We tabulate the first benchmark for detecting sequential facial manipulation in Table 1~3. SeqFakeFormer outperforms all SOTA deepfake detection methods in both manipulation types, under two evaluation metrics.



Recovery results
Examples of comparision between recovery results obtained by the correct inverse sequences (Mouse Out) and wrong sequences (Mouse Over). Experiment results show that the sequence order matters for better recovering original images, which proves the importance of detecting DeepFake manipulation sequences.

@inproceedings{shao2022seqdeepfake,
title={Detecting and Recovering Sequential DeepFake Manipulation},
author={Shao, Rui and Wu, Tianxing and Liu, Ziwei},
booktitle={European Conference on Computer Vision (ECCV)},
year={2022}
}
We referred to the project page of AvatarCLIP when creating this project page.