Research Projects
Our research primarily focuses on Multimodal Large Language Model (MLLM), Embodied AI, and AI Agent, with an emphasis on perception, reasoning, and decision-making in interactive environments:
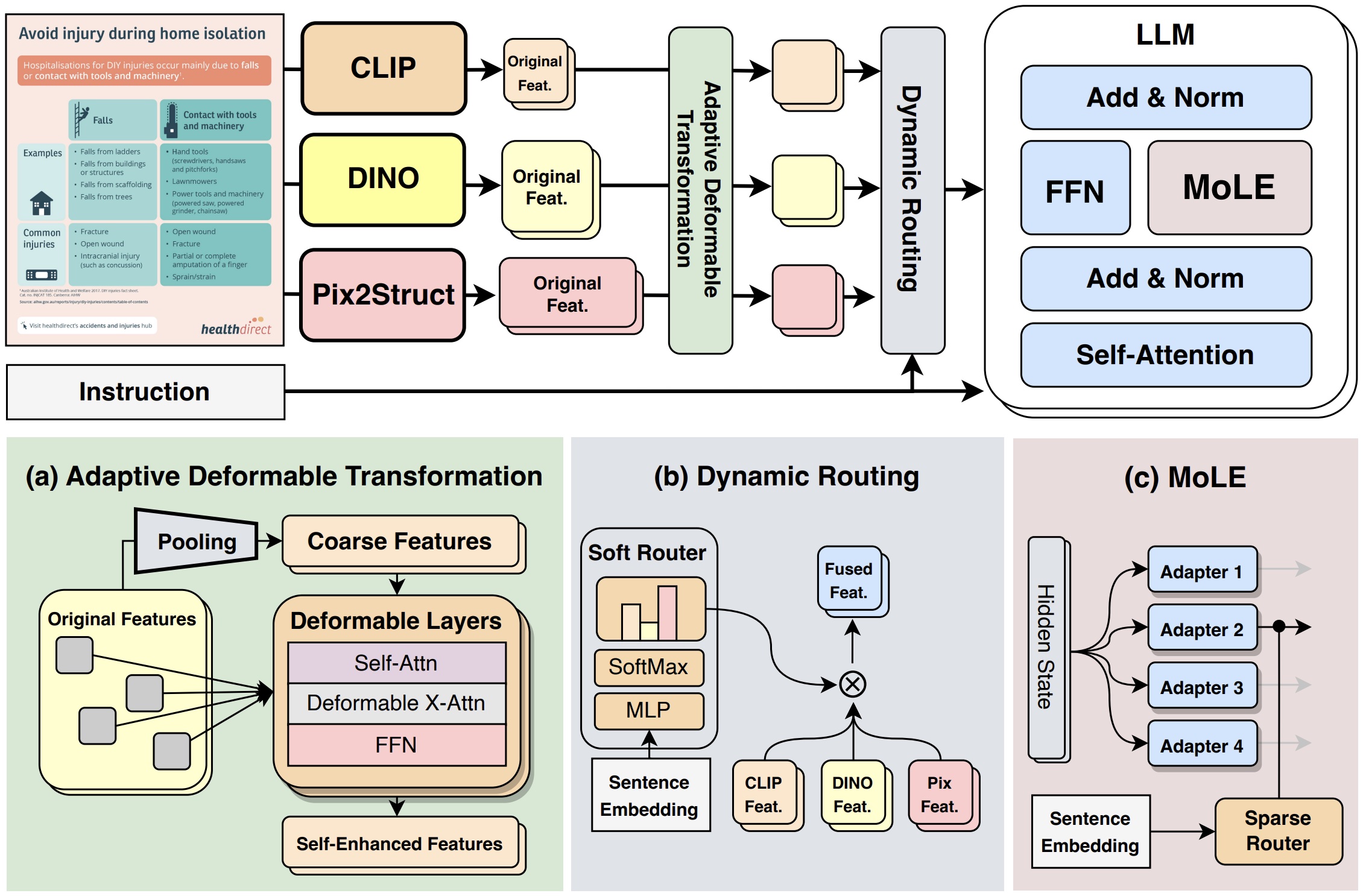
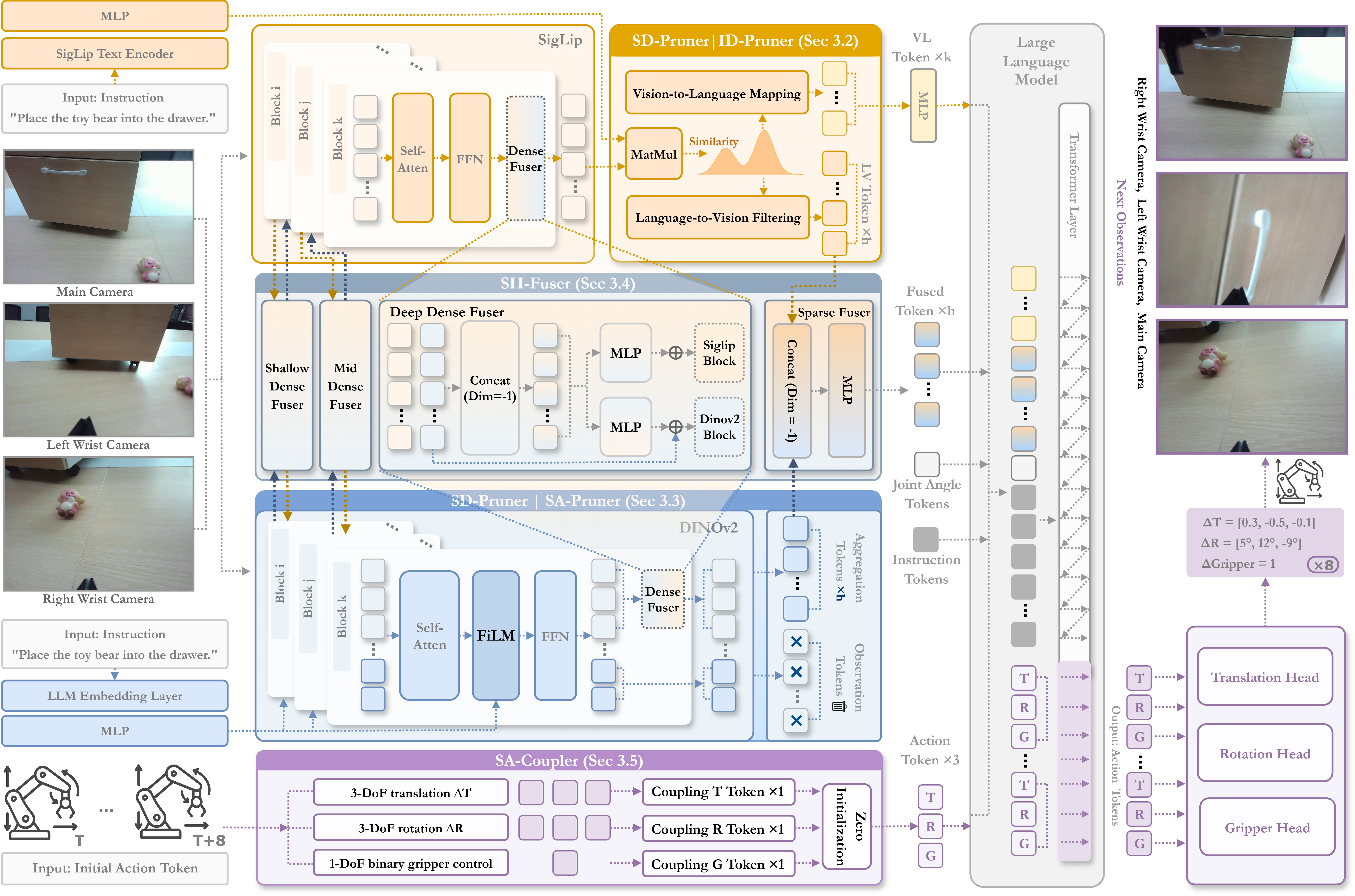
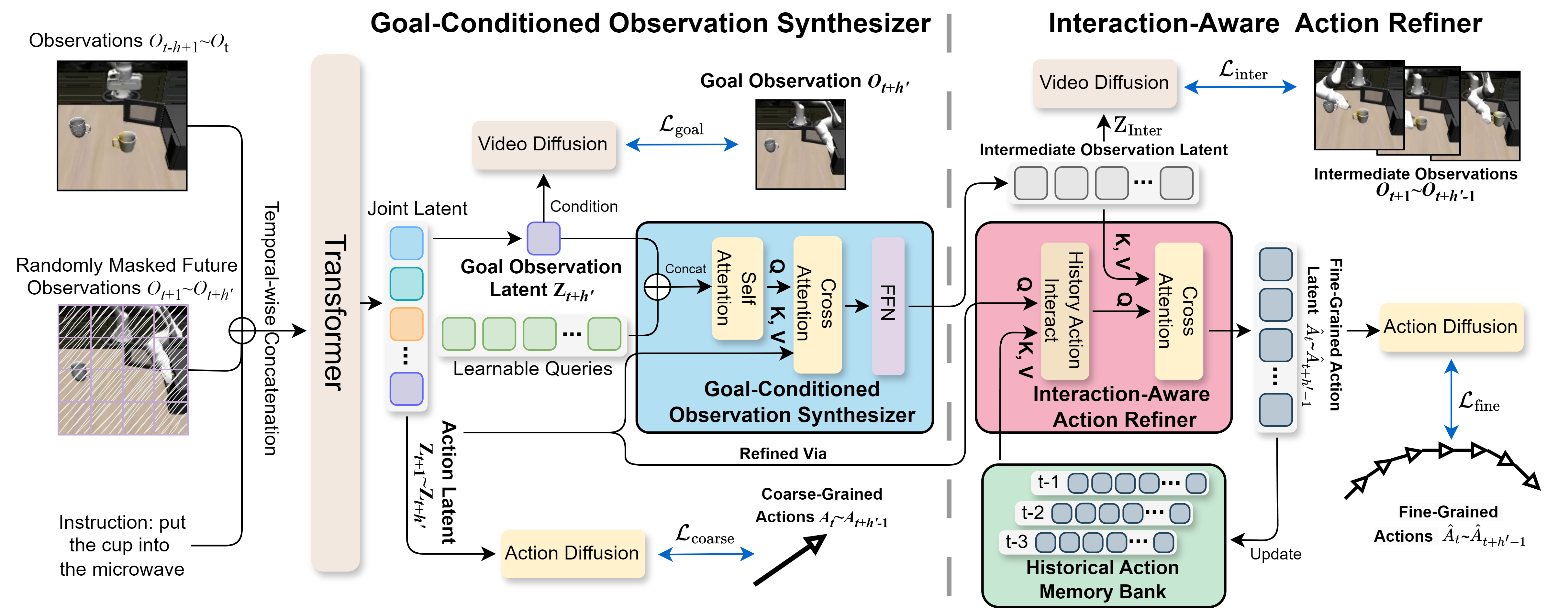
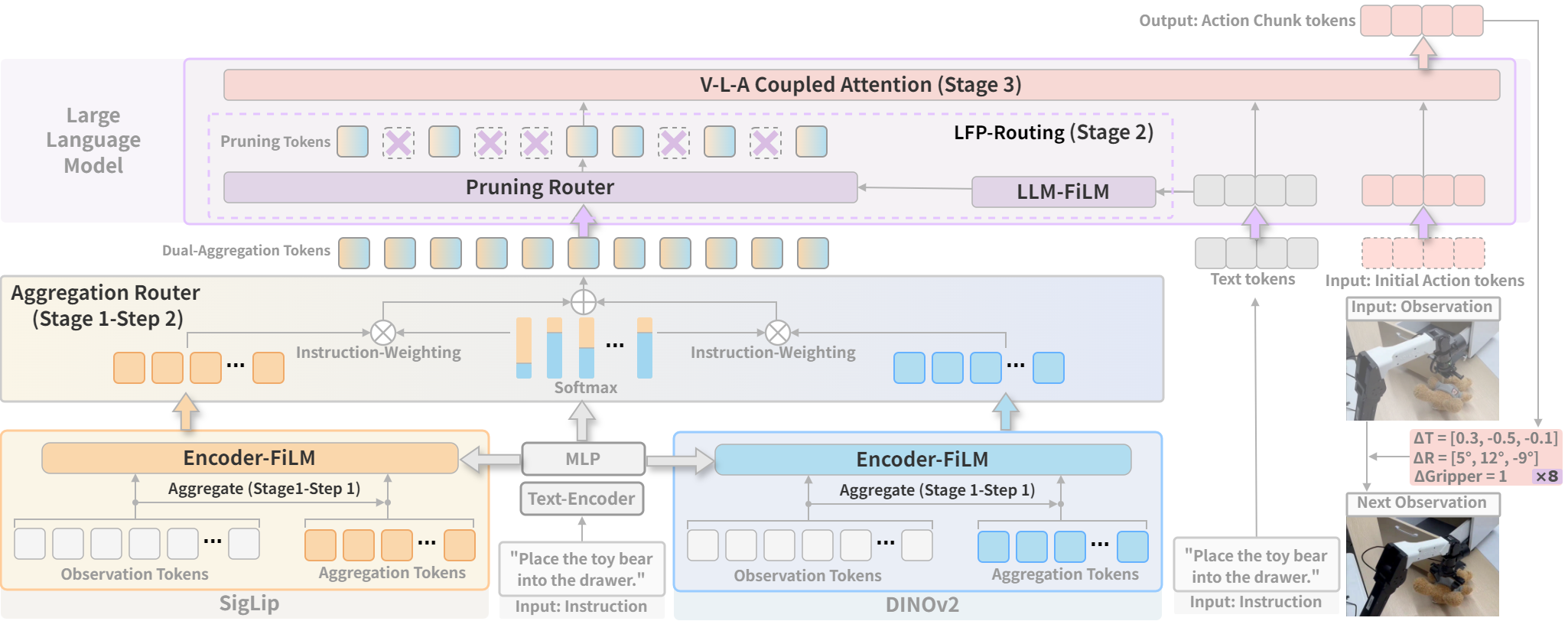
- Multimodal Large Language Models (MLLMs) aim to build and train models capable of understanding,
reasoning, and generating content across multiple modalities, including text, images, audio, and video.
Our research in this area explores the enhancement of multitask learning capabilities,
the advancement of high-resolution perception, and the design of unified architectures for
multimodal understanding and generation. Please refer to our
GitHub Orgnization about JiuTian MLLM ("九天"多模态大模型) for more details.
[bilibili]
[bilibili]
-
Embodied AI studies agents capable of perceiving, reasoning, and acting within physical environments.
We aim to build systems based on MLLMs that integrate multimodal perception, instruction comprehension, and continuous action planning
to perform complex 3D tasks such as manipulation, and interactive behaviors.
Task instruction: Open the drawer, put the toy inside, and then close it. [bilibili]
Task instruction: Fold the T-shirt carefully and finish with precise placement. [bilibili]
Task instruction: Put the bread into a bowl and heat it in the microwave. [bilibili]
Task instruction: Place both the lemon from the bowl and the apple on the table onto the plate, then put the lid on the bowl. [bilibili]
Task instruction: Grasp a plate and place it on the tablecloth. Both the plates and the tablecloths come in multiple styles. [bilibili]
Task instruction: Grasp three different fruits and place them onto the plate. For each rollout, a different combination of fruits is randomly sampled. [bilibili]
To further enhance our embodied AI research, our lab has recently acquired the R1 Lite robot from GaLaXea AI.
- AI Agent focuses on sequential decision-making across various complex environments
such as MineCraft, mobile device. We develop systems based on MLLM that span a wide range of directions, including
framework-based agents, native agents, and RL-enhanced reasoning.
[bilibili]
Task instruction: Get the search results for stay tonight near 'wembley stadium' for 1 adult. Add one result to wishlist. Confirm that this item is in the wishlist.
Task instruction: Search today's weather in Shenzhen on Chrome, then write the temperature into today.md using Markor.
Terms of Releasing Implementation:
Software provided here is for personal research purposes only. Redistribution and commercial usage are not permitted. Feedback, applications, and further development are welcome. Contact shaorui[AT]hit.edu.cn for bugs and collaborations. All rights of the implementation are reserved by the authors.